Warum verbringen wir so viel Zeit mit der Suche nach Informationen am Arbeitsplatz?
Ein Unternehmen kann Millionen von Videos, Präsentationen, Dokumenten und anderen Formen von Informationen aus verschiedenen Datenquellen besitzen. Aber ist es einfach, in dieser Masse von Daten das zu finden, was du suchst?


Ein Unternehmen kann Millionen von Videos, Präsentationen, Dokumenten und anderen Formen von Informationen aus verschiedenen Datenquellen besitzen. Aber ist es leicht, in dieser Datenmenge zu finden, was Sie suchen?
Und wie sieht es mit der Strukturierung und Kategorisierung der Daten aus? Wenn Ihr Unternehmen über 10.000 Stunden Videomaterial verfügt, ist es nicht wirklich realistisch, dass die Mitarbeiter diese Menge an Inhalten sorgfältig durchgehen und kategorisieren. Die Videos sind nur nach Titeln und Kurzbeschreibungen durchsuchbar, und der eigentliche Videoinhalt wird von der Suchmaschine nicht erfasst.
Laut einem Bericht von McKinsey verbringen Mitarbeiter täglich 1,8 Stunden mit der Suche und dem Sammeln von Informationen. Das sind im Durchschnitt 9,3 Stunden pro Woche!
Aktuelle Enterprise Search-Lösungen sind ineffizient und verschwenden am Ende Stunden von kostbarer Zeit.
Das Auffinden relevanter Informationen muss keine Suche nach der Nadel im Heuhaufen sein

Abbildung 1: Knowledge Doubling Curve von Buckminster Fuller.
Da sich die Datenmenge immer weiter vervielfacht (Abb. 1), ist es für einen Menschen unmöglich, alles zu lesen und zu markieren. Wir brauchen effizientere Methoden für den Zugriff auf die Informationen und deren Strukturierung. Glücklicherweise leben wir in einer Welt mit künstlicher Intelligenz (KI). Die KI hilft uns, große Datenmengen zu verarbeiten und auf die Informationen zuzugreifen, die sonst verloren gehen würden.
Gartner weist in seiner Analyse „Improve Search to Deliver Insight“ (2018) darauf hin, dass „Suchmaschinen auf ihrem Höhepunkt der Leistung relevante Inhalte auftauchen lassen, wann, wo und wie Mitarbeiter sie benötigen. Die Minimierung des dafür erforderlichen Aufwands maximiert den Wert für das Unternehmen.“
Bei Valamis haben wir innerhalb unserer Learning Experience Platform eine KI-Lösung entwickelt, die einen besseren Zugang zu Informationen ermöglicht. Es ist nicht nur eine leistungsstarke Unternehmenssuche, sondern beinhaltet auch ein Recommendation Engine und Analystentools, die das Beste aus den Inhalten eines Unternehmens herausholen können.
Wir nennen unsere Lösung Intelligent Knowledge Discovery (IKD) In diesem Blog tauchen wir ein in die Vorteile der Lösung, erklären die Technologie dahinter und zeigen, wie unsere Kunden sie nutzen.
Intelligent Knowledge Discovery setzt das Wissen frei
Intelligent Knowledge Discovery ist eine Lösung, die Ihnen hilft, auf einfache Weise Zugang zu allen Informationen zu erhalten, die Ihr Unternehmen hat, zusätzlich zu MOOCs und anderen Ressourcen. In der Intelligent Knowledge Discovery haben wir mehrere IBM Watson Anwendungen zu einem umfassenden und präzisen Wissensmanagementsystem verknüpft.
Die KI-basierte Lösung nutzt Natural Language Processing (NLP), Visual Recognition und maschinelles Lernen, um alle Ihre Inhalte durchzugehen und zu analysieren. Sie kombiniert menschliche Sprache und Bilder in einer Form, die eine Maschine verstehen, interpretieren, verarbeiten, analysieren und dann manipulieren kann.
Die Lösung erkennt Momente in Ihren Videos, taggt Inhalte und kategorisiert sie nach Thema oder Konzept. Sie liest alle Ihre Dokumente und schaut sich alle Ihre Videos an, so dass Sie das nicht machen müssen. Und wenn Sie das nächste Mal nach etwas suchen, wird es Sie genau auf den Moment im Video hinweisen, in dem die gesuchten Informationen gefunden werden können.
Wenn Ihr Unternehmen über 10.000 Stunden Videomaterial verfügt, würde es nach unserer Schätzung 20.000 Arbeitsstunden von einem Arbeiter benötigen, um die Videos anzusehen, alle Momente im Video zu erfassen und zu markieren.
Watson kann die gleiche Arbeit in 10 Stunden erledigen.
Und vielleicht möchten Sie später Ihre Kategorisierung ändern, die Momente noch genauer markieren oder die Zusammenhänge zwischen zwei verschiedenen Themen in Ihrem gesamten Videomaterial finden. Es würde wahrscheinlich weitere 20.000 Stunden dauern, bis der menschliche Arbeiter das alles erledigt hätte.
Die IBM Watson-Technologie kann das in weniger als 10 Stunden erledigen. Man kann Watson beibringen, genauer bei der Verarbeitung des Inhalts zu sein, die wertvollsten Informationen zu finden, und es kann dies in einem Bruchteil der Zeit tun, die ein menschlicher Arbeiter benötigen würde.
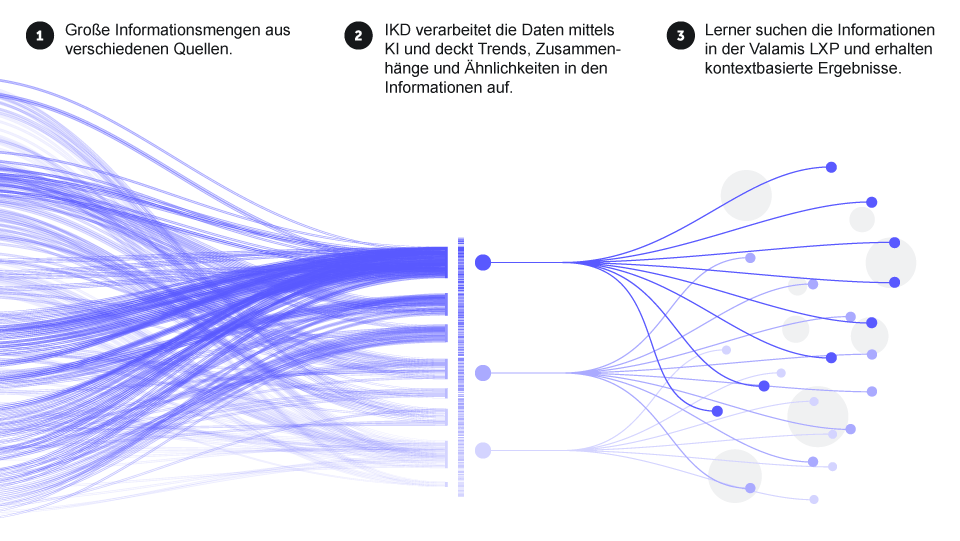
Abbildung 2.
Intelligent Knowledge Discovery ist nicht nur eine Suche, sondern kann auch intelligente Empfehlungen aussprechen. Sie kann sogar Trends, Ähnlichkeiten und Verbindungen zwischen verschiedenen Videos und verschiedenen Textteilen und anderen Inhalten erkennen. Sie kann dann die Zusammenhänge mit dem vergleichen, woran die Lernenden gerade arbeiten, so dass die Inhalte je nach den Bedürfnissen des einzelnen Lernenden sehr zielgerichtet und relevant sein können.
Cognitive Search versteht, worum es in Ihren Dokumenten und Dateien geht
In diesem Abschnitt vertiefen wir die Technologie hinter Watson und Intelligent Knowledge Discovery. In IKD spielen kognitive Such- und KI-Lösungen eine wichtige Rolle bei der Verarbeitung der realen menschlichen Sprache.
Cognitive Search verwendet Natural Language Processing (NLP) und Machine Learning, um Daten aus mehreren Datenbanken zu erfassen, zu verarbeiten, zu verstehen, zu strukturieren und zu reformieren. NLP bezieht sich auf die Fähigkeit von Computern, den Menschen in seiner natürlichen Sprache zu verstehen und mit ihm zu kommunizieren. NLP ist in unserem Alltag präsent, ohne dass wir es überhaupt bemerken. Stellen Sie sich vor, Sie schreiben eine SMS auf Ihrem Handy oder schreiben ein Dokument auf Ihrem Computer und Sie machen einen Fehler. Durch NLP werden diese Fehler erkannt und Alternativen vorgeschlagen.
Im Fall der Intelligent Knowledge Discovery könnte ein Prozess etwa so aussehen:
In 30 Minuten startet Ihre Präsentation und Sie haben Angst davor. Sie wollen schnell herausfinden, wie Sie Ihre Präsentationsangst und Ihren Stress abbauen können. Sie erinnern sich, dass es in der Lernplattform Ihres Unternehmens einige Lektionen über Reden in der Öffentlichkeit gibt, aber Sie möchten nur einige schnelle Tipps zum “Überleben” finden.
Vor Jahren hätten Sie versuchen müssen, mit Schlüsselwörtern zu suchen, um einen Kurs, ein Dokument oder ein Video zu finden.
Mit Cognitive Search können Sie die Datenbank viel schneller durchsuchen, da NLP bereits sowohl das Text- als auch das Videomaterial analysiert hat. Es wird die Antwort für Sie finden und Sie auf eine spezifische Stelle im Text oder im Video hinweisen. NLP kann beispielsweise die drei besten Tipps und eine 5-minütige Übung finden, so dass Sie immer noch genügend Zeit für die Vorbereitung haben.
Dies alles ist möglich, weil die Kombination von NLP und die durch maschinelles Lernen unterstützte Cognitive Search:
- Jede Art von Daten versteht, die Sie damit verlinkt haben.
- Big Data verarbeiten kann.
- In Ihre Learning Experience Platform eingebunden werden kann und von jedem genutzt werden kann.
Natural Language Processing auf einen Blick
Bei der Verarbeitung natürlicher Sprache geht es darum, Werkzeuge, Techniken und Algorithmen einzusetzen, damit ein Computer in natürlicher Sprache lesen und schreiben kann. Um zu erkennen, wie das funktioniert, müssen wir verschiedene NLP-Probleme und -Aspekte durchgehen, um zu sehen, wie NLP funktioniert. NLP kann in drei Kernkomponenten unterteilt werden:
- Umwandlung von Informationen in eine natürliche Sprache
- Verstehen der natürlichen Sprache
- Generierung natürlicher Sprache

Abbildung 3.
Diese 3 Kernkomponenten können in eine NLP-Pipeline aufgeteilt werden, einen Workflow mit mehreren aufeinanderfolgenden Schritten.
Umwandlung von Informationen in natürliche Sprache
Der erste Schritt der Pipeline besteht darin, natürlichsprachliche Daten in Form von Videos, Bildern und Sprache zu sammeln und die Wörter in Textformat umzuwandeln.
In diesem Schritt werden Spracherkennungs- und Zeichenerkennungswerkzeuge konfiguriert, die in den letzten Jahren erhebliche Leistungssteigerungen erfahren haben.
Manchmal werden fortgeschrittenere Werkzeuge benötigt. Es ist beispielsweise ein weiteres Werkzeug notwendig, um einen Sprecher aus einem anderen Video zu erkennen.
Natürliches Sprachverständnis ermöglicht die Kontextualisierung
Bei Daten im Textformat benötigen wir Natural Language Understanding (NLU). Dies ist ein wichtiger Bestandteil eines erfolgreichen NLP. NLU konzentriert sich auf die Umwandlung von Text in eine strukturierte Form, die von Maschinen verstanden und umgesetzt werden kann.
Text zu verstehen ist eine einfache Aufgabe für einen Menschen, aber eine schwierige Aufgabe für Maschinen–Englisch zu verstehen ist sehr schwierig. Und marginale, komplexere Sprachen wie Finnisch oder Schwedisch sind noch schwieriger!
NLU ist nicht einfach nur das Trainieren eines Gerätes zum Verständnis des Vokabulars oder das Zählen von Keyword-Frequenzen. Es beinhaltet mehrere Schritte, den Text aufzubrechen und einer Maschine beizubringen.
Die Textvorverarbeitung ist im Wesentlichen die Reinigung und Formatierung des Textes. Es gibt viele Besonderheiten, mit denen man sich auseinandersetzen muss: falsche Aussprache, Umgangssprachausdrücke, Abkürzungen und zusammengesetzte Wörter. Auf diese Weise kann die Maschine die Kommentare und Rückmeldungen Ihrer Mitarbeiter zu einem Kurs verstehen und steht der Suche als neue Peer-to-Peer-Information zur Verfügung, die ursprünglich nicht in Ihrem Lernmaterial enthalten waren.
Nach der Vorverarbeitung ist der nächste Schritt in NLU die Strukturanalyse. In jeder natürlichen Sprache gibt es eine allgemeine Struktur und Syntax, die bestimmt, wie einzelne Wörter zu Phrasen, Klauseln und Sätzen kombiniert werden. Gängige Schritte in der Strukturanalyse sind die Aufteilung von Text in Sätze und dann in einzelne Wörter. Diese Wörter werden dann mit ihrem Wortteil versehen und die grammatikalische Struktur eines Satzes wird dann mittels Parsing-Algorithmen analysiert. Das Verständnis einer Maschine für Struktur und Syntax zu entwickeln, so dass sie beispielsweise den Unterschied zwischen Verben und Substantiven erkennen kann, ist für viele andere Schritte von NLP von Vorteil, wie z. B. die Textklassifizierung durch maschinelles Lernen.
Und schließlich gibt die semantische Analyse der NLU die Möglichkeit, die Bedeutung und den Kontext zu verstehen. Die bekanntesten Anwendungsfälle der semantischen Analyse sind die automatische Keyword-Erkennung (Tagging) und das Verständnis der im Text beschriebenen Emotionen (Sentimentanalyse). Eine ausgefeiltere semantische Analyse ist jedoch ein sich ständig weiterentwickelnder Bereich, der darauf abzielt, sowohl die Person als auch den Inhalt verstehen zu können. Hier ist ein Beispiel:
Sie suchen im Inhalt nach dem Stichwort: “Tiger” und die Ergebnisse sind:
- Ein Tier
- Ein Tierkreiszeichen
- Ein Film
- Ein Bier
- Ein Panzer
- Ein Betriebssystem von Apple
Eine ausgefeiltere semantische Analyse ist daher in der Lage, Ihnen den Kontext, für den Sie sich interessieren und eine reibungslosere Benutzerführung zu bieten.
Machine Learning erkennt die verborgenen Strukturen
Der letzte Bereich der NLU ist das maschinelle Lernen. NLP-Entwickler können Modelle durch überwachtes oder unbeaufsichtigtes Lernen trainieren. Überwachtes Lernen bedeutet Textklassifizierung und erfordert eine Vielzahl von beschrifteten Daten. Unüberwachtes Lernen oder Clustering ist ein weiterer Bereich des angewandten maschinellen Lernens, mit dem versteckte Strukturen, Themen oder ähnliche Dokumente erkannt werden können. Beim maschinellen Lernen konzentrieren Sie sich auf das Thema als Klassifizierungsproblem, anstatt die Bedeutung zu verstehen. Das maschinelle Lernen ist schnell und es interessiert sich nicht für die Feinheiten der natürlichen Sprache, solange es genügend Trainingsdaten gibt. Maschinelles Lernen ist großartig darin, bestimmte begrenzte Erkenntnisse, wie z. B. über die allgemeine Stimmung, zu erlangen.
In der Realität ist die strukturelle und semantische Analyse zeitaufwendig. Es ist schwierig, eine Sammlung relevanter Muster für die natürliche Sprache zu erhalten, da sich die natürliche Sprache ständig weiterentwickelt. Sowohl traditionelle NLP-Komponenten als auch maschinelles Lernen sind erforderlich. In Intelligent Knowledge Discovery haben wir sowohl NLP als auch maschinelles Lernen integriert. Alle diese Techniken und Schritte fließen in eine Reihe von Anwendungen, die in die Cognitive Search, Geschäftsprozesse und einen Chatbot integriert werden können. All dies kann in die Intelligent Knowledge Discovery-Lösung von Valamis integriert werden. Traditionelles NLP bietet eine einfache Ebene der Analyse und Kontextualisierung. Machine Learning-Modelle nutzen die Ergebnisse der Basisschicht und bieten eine höhere Analyseebene, um Strukturen, Themen und Absichten zu erkennen.
Wie man das Wissen in einem großen Unternehmen behält: Ein Fallbeispiel
Unser Kunde, ein großes Unternehmen aus den USA, steht vor einem Problem, wenn seine langjährigen Mitarbeiter in den Ruhestand gehen. Riesige Mengen an wertvollem Wissen laufen Gefahr, zu verschwinden, wenn Menschen das Unternehmen verlassen. Um so viele Informationen wie möglich zu speichern, entschied sich das Unternehmen für Intelligent Knowledge Discovery.
Sie beschlossen, ihre Mitarbeiter während des Erzählens auf einem Video aufzuzeichnen, um ihr Wissen zu speichern. Unmengen von Videomaterial in Kombination mit Dokumenten und Präsentationen, die über Jahrzehnte gesammelt wurden, bedeuten einen riesigen Schatz an wertvollem Wissen.
Um dieses Wissen zugänglich zu machen, strukturiert die Intelligent Knowledge Discovery-Lösung die Informationen, und die kognitive Suche hilft jedem Benutzer, die gesuchten Informationen zu finden.
Lernen Sie Jack kennen
Jack ist ein langjähriger Mitarbeiter in der Organisation und steht kurz vor dem Ruhestand. Jack hat eine Menge stilles Wissen, das nie aufgeschrieben wurde.
Jack hat beschlossen, 2 Stunden pro Woche zu nutzen, um sein Wissen zu dokumentieren. So öffnet er jeden Dienstag und Donnerstag, bevor er etwas anderes macht, seinen Computer und schaltet die Webcam ein. Er wählt ein Thema aus und spricht eine Stunde lang darüber, speichert das Video in der Wissensdatenbank und geht dann zu seinen anderen Aufgaben über.
Intelligent Knowledge Discovery verarbeitet das Video, vergleicht es mit anderen Inhalten und setzt das Thema und die Tags, indiziert es dann und stellt es jedem innerhalb des Unternehmens zur Verfügung. Jacks Wissen ist jetzt gespeichert und leicht zugänglich für die zukünftigen Mitarbeiter des Unternehmens.
Gebündelte Suche stellt noch mehr Informationen zur Verfügung
Intelligent Knowledge Discovery kann auch über Ihre Integrationen auf Informationen zugreifen. IKD stellt den Suchmaschinenindex aus externen Quellen wie OpenSesame, Linkedin Learning und edX zur Verfügung. Es kann auch alle internen Dokumente außerhalb der Lernplattform aus Quellen wie Google Drive, OneDrive, DropBox und Slack ansprechen.
Aus Benutzersicht nutzt Intelligent Knowledge Discovery die Leistungsfähigkeit mehrerer Suchmaschinen in einer Suche. Dies spart Zeit für ein L&E-Team, da nicht das gesamte Material selbst produziert oder der Learning Experience Plattform des Unternehmens hinzugefügt werden muss. Obwohl das Material nicht auf der Lernplattform hinzugefügt wird, können Nutzer-Engagement und andere Learning Analytics dennoch über xAPI-Statements eingesehen werden, was zu einem allumfassenden Lern-Ökosystem führt.
Mehr als eine Unternehmenssuche
Sobald Intelligent Knowledge Discovery alle Ihre Inhalte unter Nutzung seiner maschinellen Lernfähigkeiten verarbeitet hat, kann es analysieren, wonach die Lernenden suchen und welche Konzepte am interessantesten erscheinen.
Intelligent Knowledge Discovery kann Ihnen helfen, zu erkennen, ob es eine Lücke in den Lernmaterialien gibt. Auf diese Weise können Sie den Prozess zur Erstellung neuer und relevanterer Lernmaterialien für Ihre Mitarbeiter einleiten, die sie bei ihrer täglichen Arbeit unterstützen. In einigen Fällen können Sie sogar eine sich abzeichnende Krise innerhalb eines Projekts erkennen.
Wenn IKD hilft, die Qualifikationslücken und den Lernbedarf zu erkennen, sobald sie entstehen, können Sie proaktiver handeln und Kosten senken.
Eine weitere mögliche Anwendung für Intelligent Knowledge Discovery ist, Ihnen beim besseren Erkennen von Experten in Ihrem Unternehmen zu helfen, damit Sie die richtigen Personen mit den richtigen Teams verbinden können. Wenn Sie herausfinden, wer in Ihrem System was sucht und wer was lernt, können Sie Fachkräfte finden und gezielter auf Jobaufgaben eingehen. Dies kann auch helfen, ungenutzte Potenziale bei Ihren Mitarbeitern zu finden.
Das bessere Wissensmanagement
„Die LXP benötigt nicht nur intelligente Methoden, Inhalte zu empfehlen […], sie können auch zur Empfehlung von externen Artikeln und zum Auffinden von Experten genutzt werden, und potenziell können Sie Dokumente, Videos und andere digitale Inhalte indizieren. In gewissem Sinne sind sie Inhaltsverwaltung und Lernsysteme zugleich – was der Grund für das schnelle Wachstum des Marktes ist.“
– Josh Bersin, Industrie-Analyst, Learning Experience Platform (LXP) Market Grows Up: Now Too Big To Ignore
Industrie-Analyst Josh Bersin ist der Meinung, dass es eine steigende Nachfrage für die in diesem Blogbeitrag beschriebene Funktion gibt. Intelligent Knowledge Discovery als Teil des organisatorischen Lernens entwickelt sich ständig weiter. Die Technologie ist einfach zu nutzen und zu bedienen und ermöglicht ein besseres Wissensmanagement in Unternehmen.
Aus lerntechnischer Sicht bereichert Intelligent Knowledge Management sowohl den Inhalt als auch die von den Lernenden gesammelten Daten. Die verfügbaren Daten und Informationen vervielfachen sich, da alle verfügbaren Informationen von der Maschine ausgewertet und getaggt werden können.
Auch die verfügbaren Daten aus der Nutzung der Informationen vervielfachen sich und ermöglichen eine Weiterentwicklung der Inhaltsanalyse. Der Zusammenhang zwischen Arbeit und Lernaktivitäten kann deutlich gemacht werden, da das persönliche Lernen spezifischer wird.
Das qualitative Feedback aus der Suche wird über gute Überschriften, auch bekannt als Clickbait, hinausgehen. Das bedeutet, dass die Lernenden nicht automatisch zu dem Video oder Artikel geleitet werden, die am häufigsten angeklickt wurden, sondern zu dem, der tatsächlich den am besten geeigneten Inhalt hat.
Derzeit fragen alte Suchmaschinen die Nutzer: “War dieses Suchergebnis für Sie nützlich?”. In Zukunft werden Unternehmen über ein Werkzeug verfügen, das die Antwort auf die Frage selbstständig findet, indem es das Suchwerkzeug und die Lernanalyse kombiniert und die Aktivitäten der Lernenden aufzeichnet. Hat der Benutzer auf eines der Suchergebnisse geklickt? Wie viel Zeit haben sie damit verbracht, die Materialien zu studieren?
Basierend auf den Lerndaten wird das System in der Lage sein, die Qualität der Suchresultate und des Inhalts zu bewerten. Man kann ableiten, ob der Lernende nicht gefunden hat, was er gesucht hat, und die zukünftigen Suchergebnisse darauf aufbauend ändern.
Im Zuge des technologischen Fortschritts kann und wird das menschliche Gehirn mit Computern und künstlicher Intelligenz verschmolzen werden. Oder die Peer-to-Peer-Informationen könnten per Gedanken übertragen werden – mit etwas Hilfe einer Maschine.
Wir leben vielleicht noch nicht in der Matrix, aber vielleicht wird das in unserer Arbeit benötigte Wissen in unseren Köpfen verankert sein, bevor wir überhaupt daran denken, danach zu suchen.


